ClickHouse Cloud Console 모니터링
ClickHouse Cloud의 서비스에는 대시보드와 알림을 제공하는 기본 제공 모니터링 구성 요소가 포함되어 있습니다. 기본적으로 Cloud Console의 모든 사용자는 이러한 대시보드에 액세스할 수 있습니다.
대시보드
서비스 상태
서비스 상태 대시보드는 서비스의 전반적인 상태를 모니터링하는 데 사용할 수 있습니다. ClickHouse Cloud는 서비스가 유휴 상태일 때도 볼 수 있도록 시스템 테이블에서 이 대시보드에 표시되는 메트릭을 수집하고 저장합니다.
리소스 사용률
Infrastructure 대시보드는 ClickHouse 프로세스에서 사용 중인 리소스를 자세히 보여줍니다. ClickHouse Cloud는 서비스가 유휴 상태일 때도 볼 수 있도록 시스템 테이블에서 이 대시보드에 표시되는 메트릭을 수집하고 저장합니다.
메모리 및 CPU
Allocated CPU 및 Allocated Memory 그래프는 서비스의 각 레플리카에 사용할 수 있는 총 컴퓨트 리소스를 표시합니다. 이러한 할당은 ClickHouse Cloud의 scaling 기능을 사용해 변경할 수 있습니다.
Memory Usage 및 CPU Usage 그래프는 쿼리는 물론 병합과 같은 백그라운드 프로세스를 포함하여, 각 레플리카에서 ClickHouse 프로세스가 실제로 얼마나 많은 CPU와 메모리를 사용하고 있는지 추정합니다.
메모리 또는 CPU 사용률이 할당된 메모리 또는 CPU에 근접하면 성능 저하가 발생할 수 있습니다. 이를 해결하려면 다음을 권장합니다:
- 쿼리 최적화
- 테이블 엔진의 파티셔닝 변경
- scaling을 사용하여 서비스에 더 많은 컴퓨트 리소스 추가
다음은 이 그래프들에 표시되는 해당 시스템 테이블(system table) 메트릭입니다:
| 그래프 | 해당 메트릭 이름 | 집계 | 참고 |
|---|---|---|---|
| 할당된 메모리 | CGroupMemoryTotal | 최대값 | |
| 할당된 CPU | CGroupMaxCPU | 최대값 | |
| 사용된 메모리 | MemoryResident | 최대값 | |
| 사용된 CPU | 시스템 CPU 메트릭 | 최대값 | Prometheus endpoint를 통해 수집된 ClickHouseServer_UsageCores |
데이터 전송
그래프에는 ClickHouse Cloud로 들어오고 나가는 데이터 전송량이 표시됩니다. 자세한 내용은 네트워크 데이터 전송을 참조하십시오.
고급 대시보드
이 대시보드는 기본 제공 고급 관측성 대시보드를 수정한 버전이며, 각 시리즈는 레플리카별 메트릭을 나타냅니다. 이 대시보드는 ClickHouse 관련 문제를 모니터링하고 문제를 해결하는 데 유용합니다.
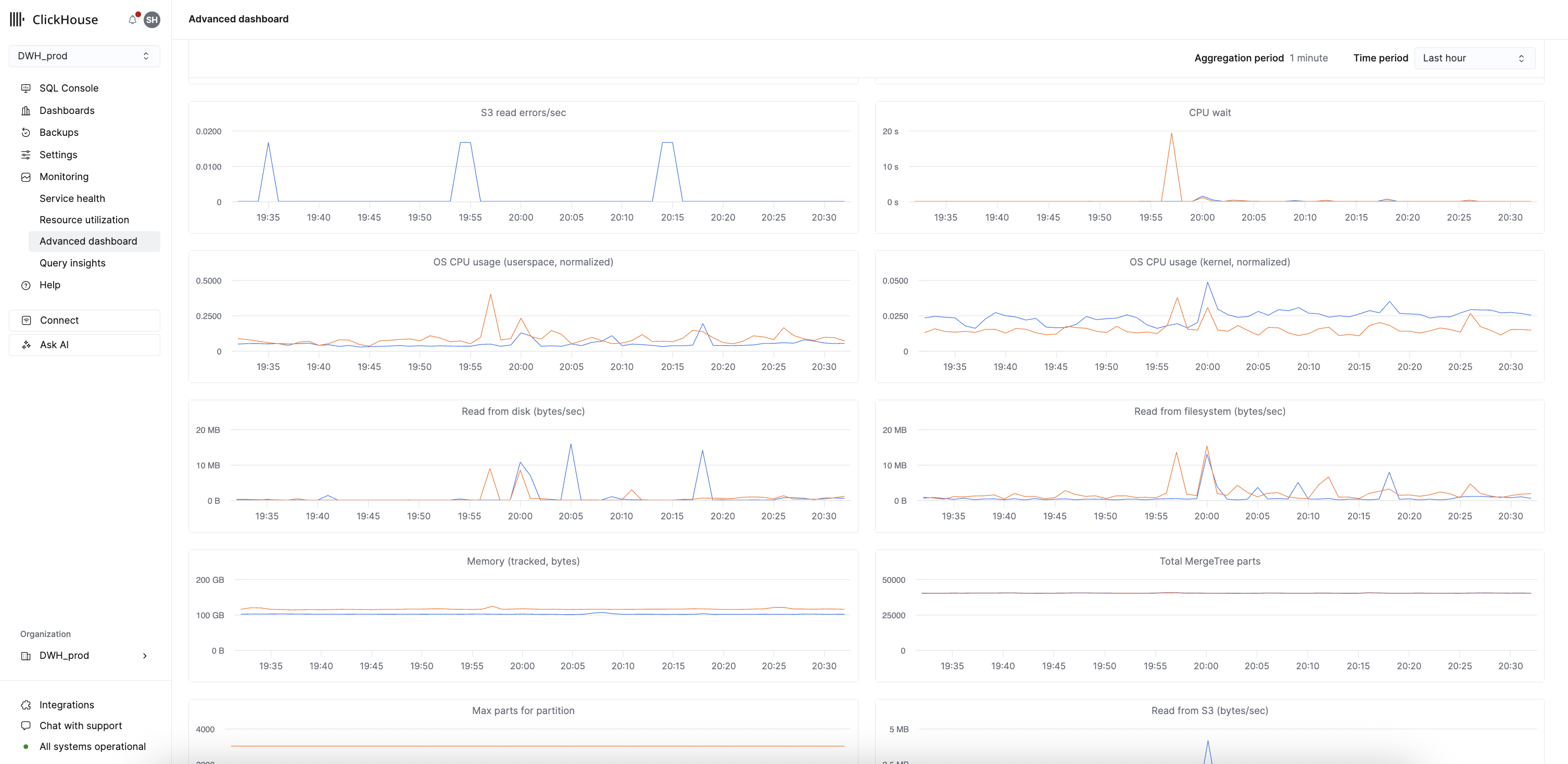
ClickHouse Cloud는 이 대시보드에 표시되는 메트릭을 시스템 테이블(system table)에서 수집하고 저장하므로 서비스가 idle 상태일 때도 확인할 수 있습니다. 이러한 메트릭에 접근해도 기본 서비스에 쿼리가 실행되지 않으며 idle 상태의 서비스를 깨우지 않습니다.
아래 표는 고급 대시보드의 각 그래프를 해당 ClickHouse 메트릭 이름, 시스템 테이블 소스, 집계 타입에 매핑한 것입니다.
| Graph | Corresponding ClickHouse metric name | System table | Aggregation Type |
|---|---|---|---|
| 초당 쿼리 수 | ProfileEvent_Query | metric_log | 합계 / bucketSizeSeconds |
| 실행 중인 쿼리 수 | CurrentMetric_Query | metric_log | 평균 |
| 실행 중인 병합 수 | CurrentMetric_Merge | metric_log | 평균 |
| 초당 선택된 바이트 수 | ProfileEvent_SelectedBytes | metric_log | 합계 / bucketSizeSeconds |
| IO 대기 | ProfileEvent_OSIOWaitMicroseconds | metric_log | 합계 / bucketSizeSeconds |
| S3 읽기 대기 | ProfileEvent_ReadBufferFromS3Microseconds | metric_log | 합계 / bucketSizeSeconds |
| 초당 S3 읽기 오류 수 | ProfileEvent_ReadBufferFromS3RequestsErrors | metric_log | 합계 / bucketSizeSeconds |
| CPU 대기 | ProfileEvent_OSCPUWaitMicroseconds | metric_log | 합계 / bucketSizeSeconds |
| OS CPU 사용량(사용자 공간, 정규화됨) | OSUserTimeNormalized | asynchronous_metric_log | |
| OS CPU 사용량(커널, 정규화됨) | OSSystemTimeNormalized | asynchronous_metric_log | |
| 디스크에서 읽기 | ProfileEvent_OSReadBytes | metric_log | 합계 / bucketSizeSeconds |
| 파일 시스템에서 읽기 | ProfileEvent_OSReadChars | metric_log | 합계 / bucketSizeSeconds |
| 메모리(추적됨, 바이트) | CurrentMetric_MemoryTracking | metric_log | |
| 전체 MergeTree 파트 수 | TotalPartsOfMergeTreeTables | asynchronous_metric_log | |
| 파티션당 최대 파트 수 | MaxPartCountForPartition | asynchronous_metric_log | |
| S3에서 읽기 | ProfileEvent_ReadBufferFromS3Bytes | metric_log | 합계 / bucketSizeSeconds |
| 파일 시스템 캐시 크기 | CurrentMetric_FilesystemCacheSize | metric_log | |
| 초당 디스크 S3 쓰기 요청 수 | ProfileEvent_DiskS3PutObject + ProfileEvent_DiskS3UploadPart + ProfileEvent_DiskS3CreateMultipartUpload + ProfileEvent_DiskS3CompleteMultipartUpload | metric_log | 합계 / bucketSizeSeconds |
| 초당 디스크 S3 읽기 요청 수 | ProfileEvent_DiskS3GetObject + ProfileEvent_DiskS3HeadObject + ProfileEvent_DiskS3ListObjects | metric_log | 합계 / bucketSizeSeconds |
| FS 캐시 적중률 | sum(ProfileEvent_CachedReadBufferReadFromCacheBytes) / (sum(ProfileEvent_CachedReadBufferReadFromCacheBytes) + sum(ProfileEvent_CachedReadBufferReadFromSourceBytes)) | metric_log | |
| 페이지 캐시 적중률 | greatest(0, (sum(ProfileEvent_OSReadChars) - sum(ProfileEvent_OSReadBytes)) / (sum(ProfileEvent_OSReadChars) + sum(ProfileEvent_ReadBufferFromS3Bytes))) | metric_log | |
| 초당 네트워크 수신 바이트 수 | NetworkReceiveBytes | asynchronous_metric_log | 합계 / bucketSizeSeconds |
| 초당 네트워크 송신 바이트 수 | NetworkSendBytes | asynchronous_metric_log | 합계 / bucketSizeSeconds |
| 동시 TCP 연결 수 | CurrentMetric_TCPConnection | metric_log | |
| 동시 MySQL 연결 수 | CurrentMetric_MySQLConnection | metric_log | |
| 동시 HTTP 연결 수 | CurrentMetric_HTTPConnection | metric_log |
각 시각화에 대한 자세한 정보와 문제 해결에 활용하는 방법은 고급 대시보드 문서를 참조하십시오.
쿼리 인사이트
쿼리 인사이트 기능은 다양한 시각화와 테이블을 통해 ClickHouse의 내장 쿼리 로그를 더 쉽게 사용할 수 있도록 해줍니다. ClickHouse의 system.query_log 테이블은 쿼리 최적화, 디버깅, 전반적인 클러스터 상태 및 성능 모니터링을 위한 핵심 정보 소스입니다.
서비스를 선택하면 왼쪽 사이드바의 Monitoring 탐색 항목이 확장되어 쿼리 인사이트 하위 항목이 표시됩니다:
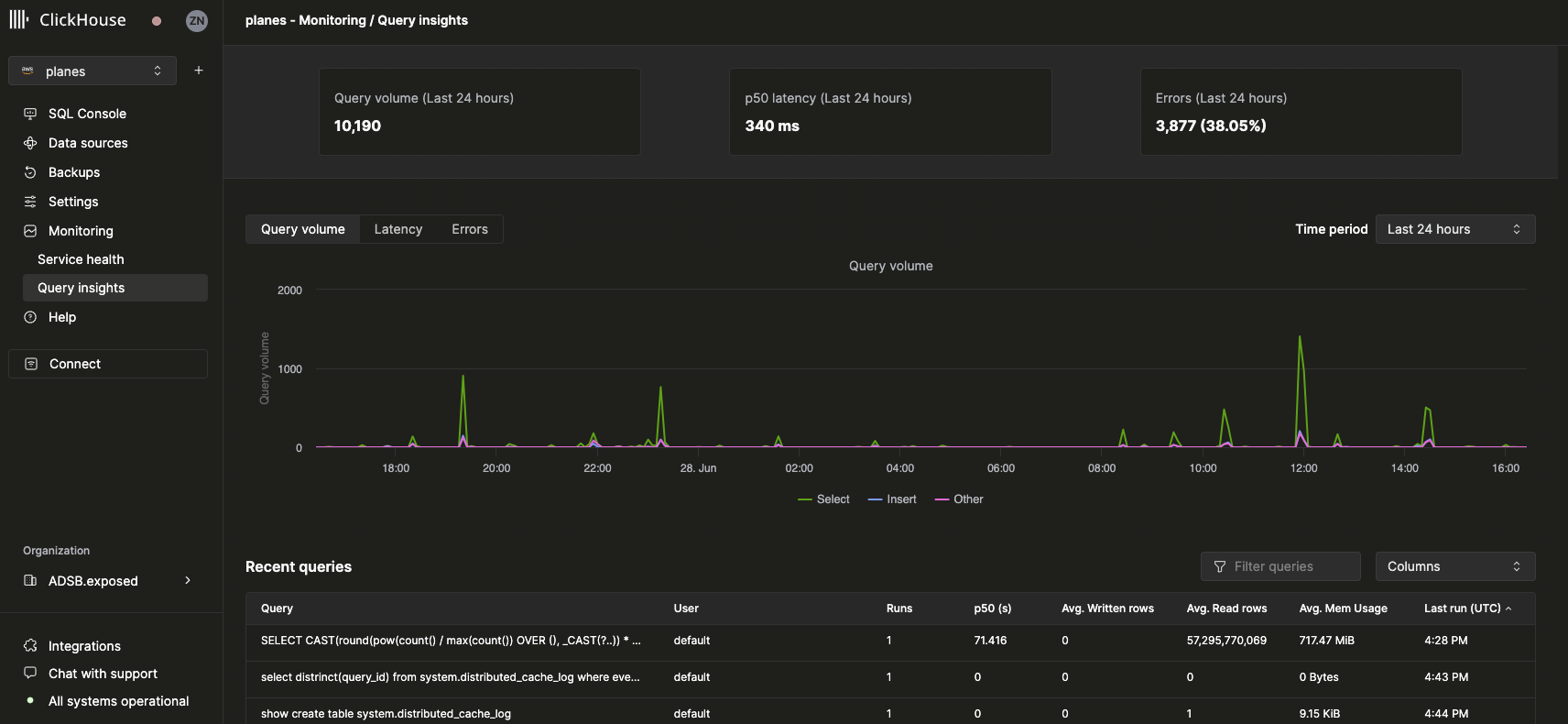
상위 수준 메트릭
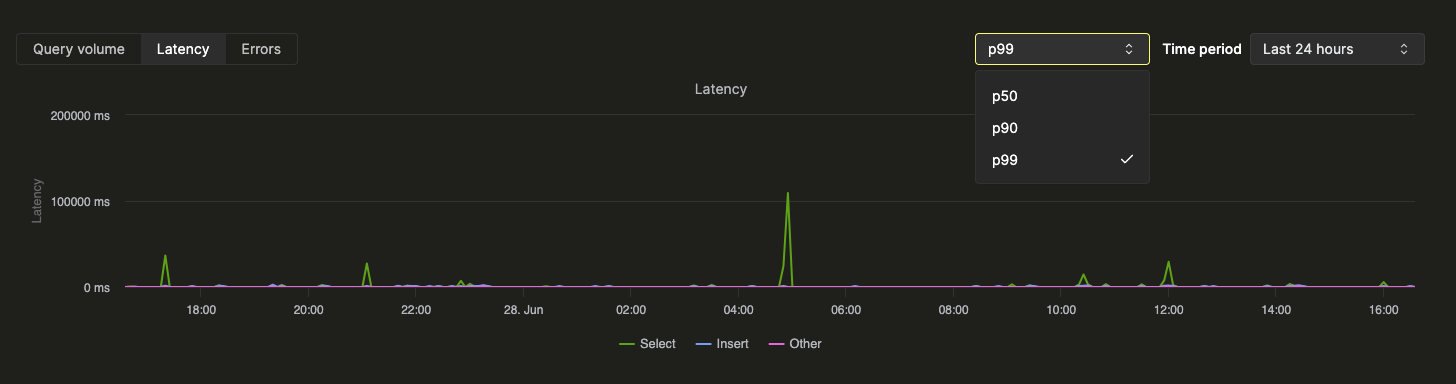
상단의 통계 상자는 선택한 기간 동안의 기본 쿼리 메트릭을 나타냅니다. 그 아래에서는 시계열 차트를 통해 쿼리 유형(select, insert, other)별로 구분된 쿼리 볼륨, 지연 시간, 오류율을 보여줍니다. 지연 시간 차트는 p50, p90, p99 지연 시간을 표시하도록 조정할 수 있습니다:
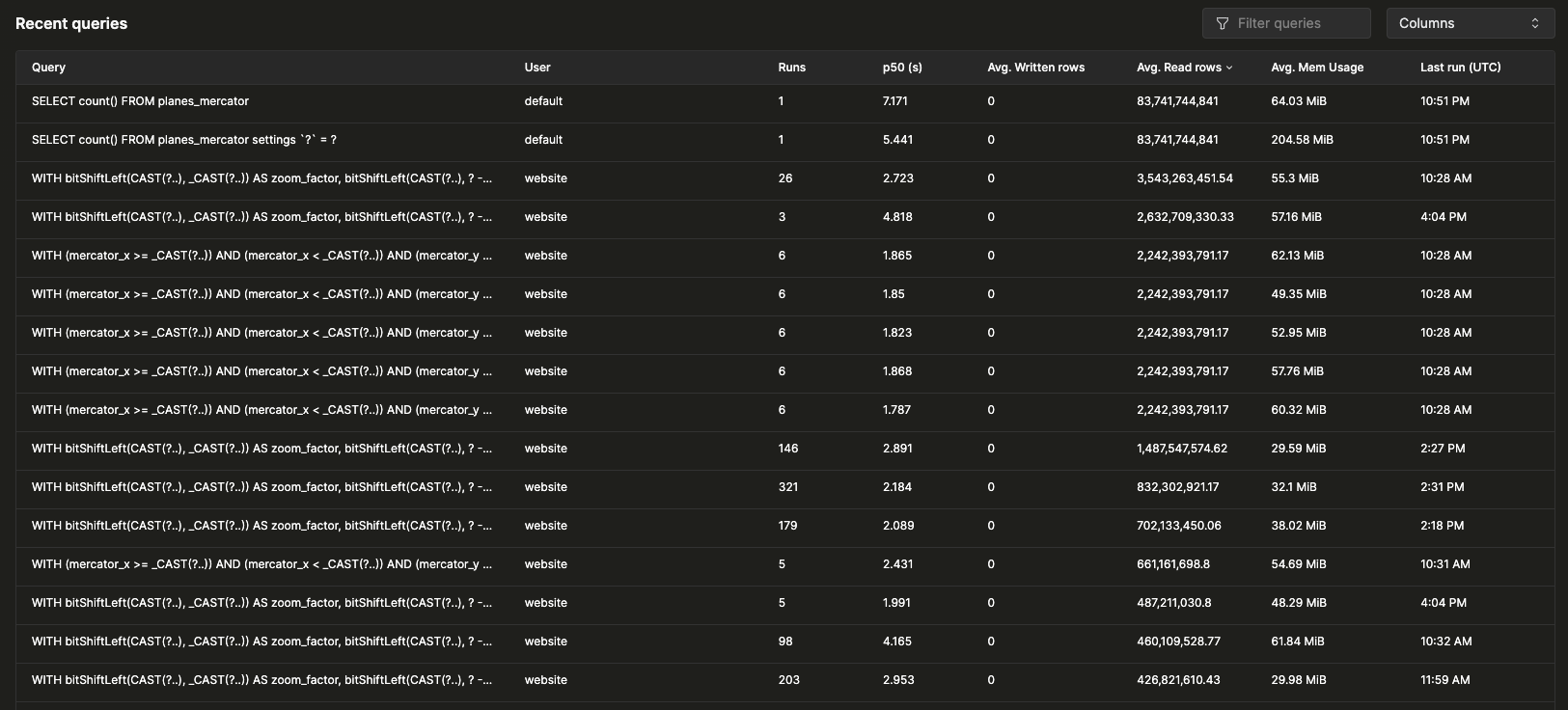
최근 쿼리
선택한 시간 범위에서 정규화된 쿼리 해시와 사용자별로 그룹화된 쿼리 로그 엔트리를 테이블에 표시합니다. 최근 쿼리는 사용 가능한 모든 필드를 기준으로 필터링하고 정렬할 수 있으며, 테이블에는 tables, p90, p99 지연 시간과 같은 추가 필드의 표시 여부도 구성할 수 있습니다:
쿼리 드릴다운
최근 쿼리 테이블에서 쿼리를 선택하면, 선택한 쿼리와 관련된 메트릭 및 정보가 포함된 플라이아웃이 열립니다:
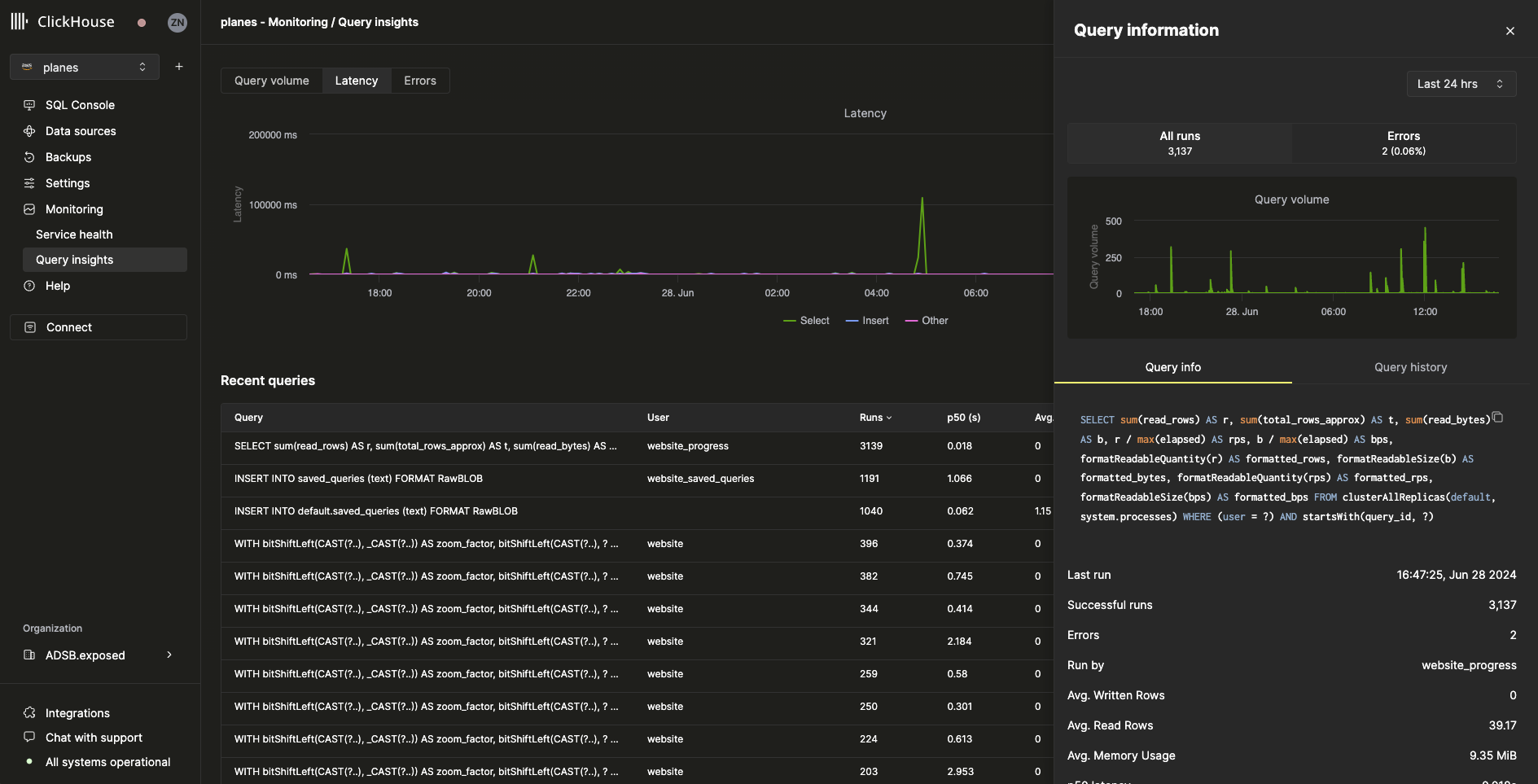
Query info 탭의 모든 메트릭은 집계 메트릭이지만, Query history 탭을 선택하면 개별 실행의 메트릭도 확인할 수 있습니다:
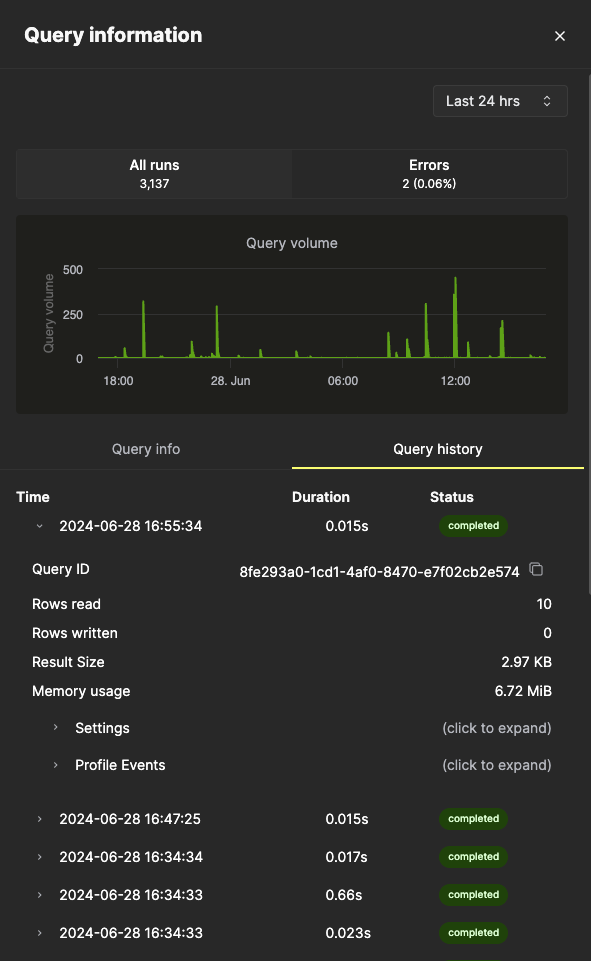
이 패널에서 각 쿼리 실행의 Settings 및 Profile Events 항목을 확장하면 추가 정보를 확인할 수 있습니다.
관련 페이지
- 알림 — 확장 이벤트, 오류, 청구에 대한 알림을 구성합니다
- 고급 대시보드 — 각 대시보드 시각화에 대한 자세한 참조
- 시스템 테이블 쿼리하기 — 심층 분석을 위해 시스템 테이블에 대해 사용자 지정 SQL 쿼리를 실행합니다
- Prometheus endpoint — 메트릭을 Grafana, Datadog 또는 기타 Prometheus 호환 도구로 내보냅니다
